O Instituto de Pesquisas Jardim Botânico do Rio de Janeiro (JBRJ), assim como várias outras instituições, produz e possui sob sua guarda um conjunto de recursos de informação variado sobre biodiversidade. Vamos considerar neste texto “recursos de informação” como sendo documentos (relatórios, dissertações, teses, publicações, etc.), planilhas (dados estruturados, tabulados sob a forma de planilhas, arquivos de texto delimitados ou bancos de dados), apresentações (séries de “slides”), imagens (estáticas ou em movimento – vídeo), livros e publicações, mapas (em formato vetorial ou “raster”) e objetos em coleções científicas.
Estes recursos de informação são resultado do investimento de recursos (tempo, conhecimento e dinheiro público), materializados sob a forma de conhecimento sistematizado sobre a biodiversidade.
 Muitos destes recursos de informação ainda estão sob o “efeito Gollum” – trancados em gavetas e computadores de pesquisadores que, por diversas razões que não pretendo aqui elaborar, consideram um equívoco compartilhar seus dados e informações. Não vamos tratar destes recursos. Vamos considerar aqui apenas recursos “libertos” (dados abertos).
Muitos destes recursos de informação ainda estão sob o “efeito Gollum” – trancados em gavetas e computadores de pesquisadores que, por diversas razões que não pretendo aqui elaborar, consideram um equívoco compartilhar seus dados e informações. Não vamos tratar destes recursos. Vamos considerar aqui apenas recursos “libertos” (dados abertos).
Pois bem. Vamos imaginar que seria razoável alguém querer saber todos os recursos de informação (ou todo o conhecimento já sistematizado) que o JBRJ já produziu ou tem sob sua guarda, sobre o pau-brasil. Esta pessoa poderia ir à biblioteca, pesquisaria sob a palavra-chave “pau-brasil” e retornaria com uma lista de livros relevantes sobre o pau-brasil (a discussão sobre se realmente todos os livros relevantes seriam encontrados não cabe aqui…). A pessoa poderia também ir ao herbário, ou ao sistema JABOT disponível na Internet, e pesquisar sobre a espécie correspondente ao nome “pau-brasil“, recebendo uma lista dos objetos existentes nas diferentes coleções. Entretanto, suponho que o resultado destas pesquisas não representa “tudo que a instituição sabe ou tem” sobre o pau-brasil. Uma miríade de recursos de informação, em formato digital ou não, de fotos a relatórios de pesquisa, de dissertações a apresentações para alunos de pós-graduação, de planilhas de análises laboratoriais a mapas de distribuição, está dispersa pela instituição.
No mundo ideal, pelo menos no meu, gostaria de ter um “agente” a quem eu perguntasse de forma solene: – “me diga tudo que o JBRJ tem sobre o pau-brasil”. Este “agente”, enquanto ainda não é um robô humanoide de feições e atitudes amáveis, poderia ser uma interface baseada na web – um site. Já está de bom tamanho!
É claro que no meu mundo ideal #2, perguntaria ao agente #2 de forma ainda mais solene: – “me diga tudo que o JBRJ sabe sobre o pau-brasil“. Reparem na diferença entre o “tudo que tem sobre” e o “tudo que sabe sobre”, pois o “tudo que tem” seria uma lista dos recursos de informação que falam ou tratam do pau-brasil. “Tudo que sabe” seria o conhecimento resumido, sistematizado e qualificado sobre o conjunto de recursos disponível. Algo parecido com que o Wolfram Alpha vem tentando fazer a vários anos, e falhando espetacularmente. Vamos ficar então com o “agente #1”, aquele que lhe entrega uma lista dos recursos de informação sobre o pau-brasil, pois é sobre essa proposta de arquitetura que este texto trata.
O que estamos fazendo no JBRJ com apoio do MCTI é desenvolver uma arquitetura baseada em ferramentas gratuitas de código livre e aberto, capazes de catalogar eletronicamente os diferentes recursos de informação, indexando estes recursos através dos escopos taxonômico, temático, 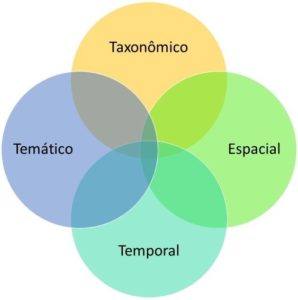 temporal e espacial, utilizando para indexação vocabulários controlados, permitindo com que uma ferramenta de busca integrada funcione exatamente como o “agente #1” – responda através de uma interface única baseada na web, tudo que o JBRJ tem sobre uma espécie, um local, um tema ou um período de tempo. A proposta consiste então em catalogar os metadados dos recursos de informação em ferramentas específicas para cada tipo de recurso.
temporal e espacial, utilizando para indexação vocabulários controlados, permitindo com que uma ferramenta de busca integrada funcione exatamente como o “agente #1” – responda através de uma interface única baseada na web, tudo que o JBRJ tem sobre uma espécie, um local, um tema ou um período de tempo. A proposta consiste então em catalogar os metadados dos recursos de informação em ferramentas específicas para cada tipo de recurso.
O Ckan (acrônimo de Comprehensive Knowledge Archive Network) é uma ferramenta de código livre e aberto baseada na web, criada para a o armazenamento, gestão e publicação de dados abertos. É utilizado em vários sites do governo federal, inclusive no Portal Brasileiro de Dados Abertos.
O DSpace foi desenvolvido para possibilitar a criação de repositórios digitais com funções de armazenamento, gerenciamento, preservação e visibilidade da produção intelectual. Os repositórios DSpace permitem o gerenciamento da produção científica em qualquer tipo de material digital, dando-lhe maior visibilidade e garantindo a sua acessibilidade ao longo do tempo. O DSpace é largamente utilizado em todo mundo. No Brasil, vem recebendo apoio e divulgação do IBICT desde 2004.
O ResourceSpace é uma ferramenta também de código livre e aberto para gerenciamento e publicação de acervos digitais, especialmente voltado para imagens, áudio e vídeo.

O GeoNode é uma plataforma livre para a catalogação e publicação de dados espaciais, em formato vetorial ou matricial. Os dados e metadados catalogados são oferecidos também como web services para acesso em outras aplicações. A EMBRAPA vem utilizando o GeoNode para publicação dos seus dados espaciais e auxiliando nossa equipe na customização da ferramenta.
Por fim, o JABOT é o sistema institucional de gestão e publicação dos dados sobre os objetos nas coleções científicas.
O que há em comum com estas ferramentas é que elas têm a funcionalidade de oferecer acesso aos seus dados não só para humanos, através da interface tradicional – uma página na Internet; mas também para outros sistemas por meio de componentes específicos – APIs e Web Services.
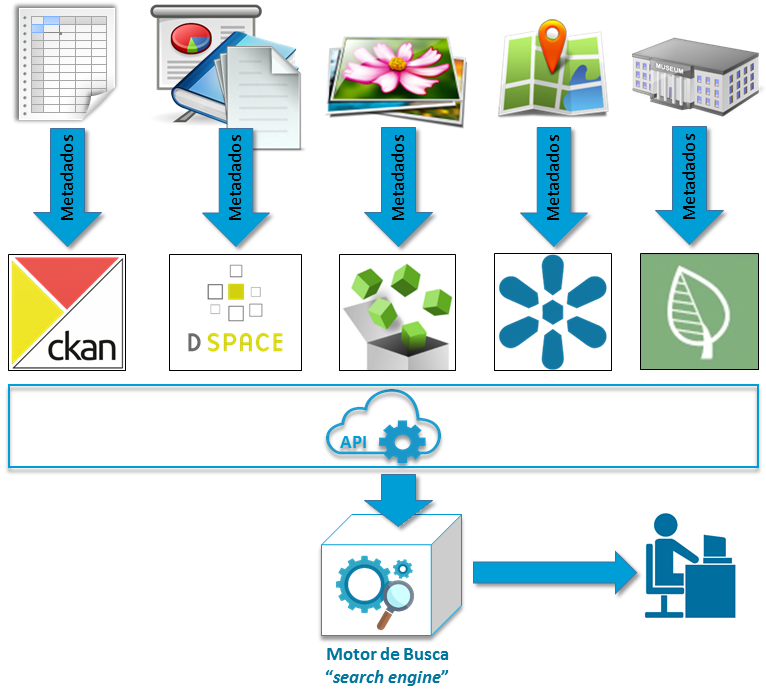
Este conjunto de API’s cria uma “camada” com capacidade de interagir com um motor de busca que armazena os metadados de todos os recursos, permitindo ao usuário consultá-los todos, de uma única vez, por meio de uma interface única. Este motor de busca encarna a figura do “agente #1” citado acima pois ele sabe tudo que cada repositório tem, retornando uma lista dos recursos de informação que atendem ao critério de busca.
Assim, por exemplo, quando o curioso usuário quer saber tudo que o JBRJ possui sobre o pau-brasil, o motor de busca responde, por exemplo, que existem planilhas no Ckan, documentos no DSpace, imagens no ResourceSpace, mapas no GeoNode e ainda exsicatas no herbário, plantas vivas no arboreto, amostras de DNA, frutos e sementes, e por aí vai.
O desafio
Instalar softwares “de prateleira”, carregá-los com metadados e integrá-los via API não é o desafio. No exemplo acima, onde o curioso usuário deseja saber o que temos sobre o pau-brasil, vamos considerar o seguinte cenário: temos exsicatas de Caesalpinia echinata no herbário, um artigo científico escrito em inglês tratando do brazilwood e um livro que fala da ocorrência da Caesalpinia obliqua, no repositório DSpace; fotos da ibirapitanga no ResourceSpace e uma planilha que trata do uso do pau-brasil pelas comunidades de Pernambuco. Todos estes termos representam a mesma entidade no mundo real.
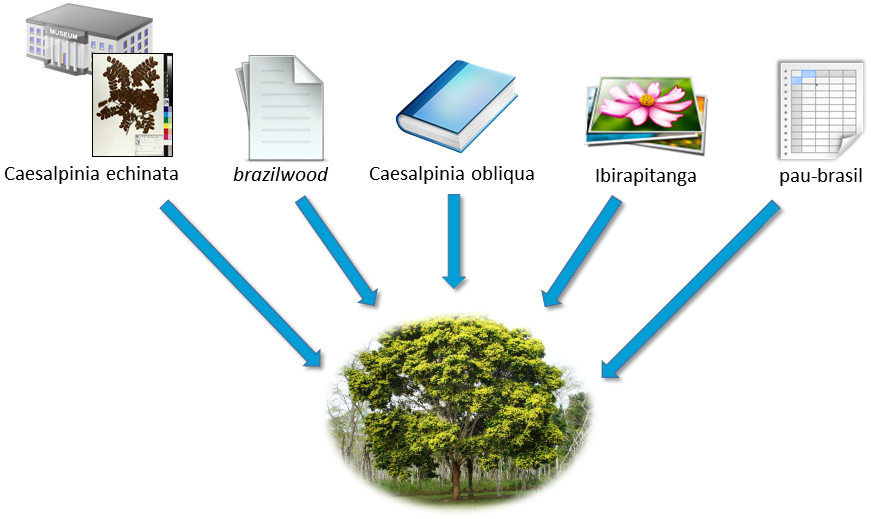
Este desafio possui aspectos teóricos e práticos. Os teóricos, de extrema relevância, têm sido abordados pela colega Andrea Albuquerque em sua carreira de pesquisadora, oferecendo um riquíssimo subsídio à abordagem do problema. Entretanto, minha abordagem aqui creio ser mais ferramental e arquitetural. Fica claro que o motor de busca citado acima precisa ser inteligente o suficiente para entender que estes diferentes termos tratam da mesma entidade, e que para atender à pergunta do curioso cidadão, a busca deve considerar estes diferentes termos de indexação pelos diferentes repositórios de recursos.
Neste caso específico, esta relação de termos está expressa em um recurso-mestre, que é a página do taxon na Flora do Brasil on-line. Porém, aprendi com o colega Ivo Pierozzi Junior que estas relações entre termos podem ser bem complexas. Por exemplo, um documento falando sobre mata de igapó deve retornar em uma consulta feita sobre floresta amazônica.
Desta forma, a peça que falta em nossa arquitetura é algo como um “servidor de termos relacionados”, que abrigaria um Tesauro sobre biodiversidade.
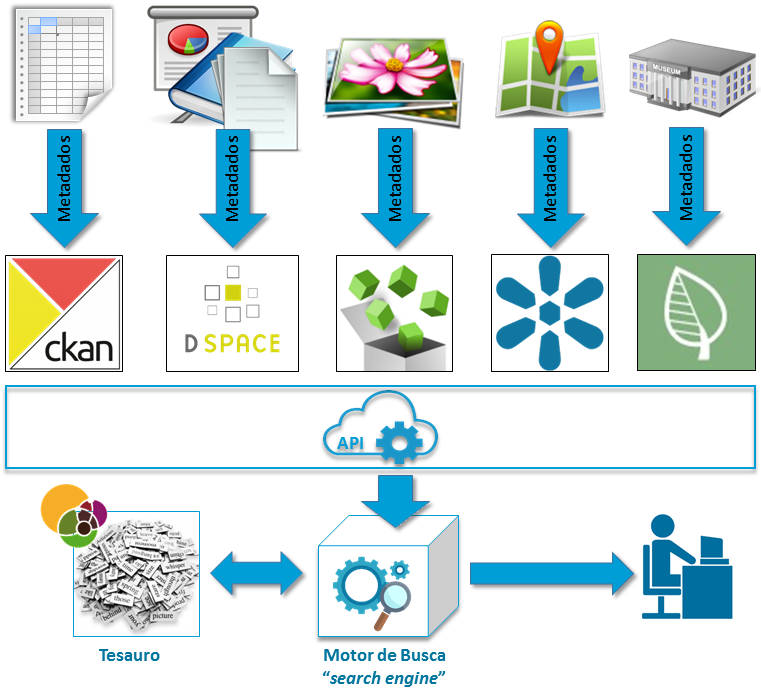
Em nossa prospecção tecnológica, identificamos uma ferramenta: o TemaTres. O TemaTres é uma aplicação baseada na web que atua como um servidor de vocabulário, permitindo manejar representações formais do conhecimento como ontologias, taxonomias, tesauros, glossários e lista de valores.
Atributos interessantes do TemaTres são que, além de possuir uma API, que pode ser explorada na conexão com o motor de busca, ele possui a funcionalidade de poder receber contribuições de termos de um grupo de usuários, geridas por um grupo de curadores, facilitando a construção colaborativa de vocabulários controlados. Além disto, é uma ferramenta de código aberto e gratuita, extensível através de plugins.
Muitas iniciativas estão usando esta ferramenta, entre elas o pessoal das Pesquisas Ecológicas de Longa Duração (LTER), que já possui um conjunto de vocabulários controlados no TemaTres.
Em nosso portal de dados, já temos disponíveis as ferramentas citadas, em diferentes graus de maturidade, incluindo uma versão de testes da TemaTres, onde contamos com a valiosa orientação do colega Ivo Pierozzi Junior da EMBRAPA.
Estamos avaliando algumas ferramentas para o motor de busca, como a solução Open Semantic Search e outras de mais “baixo nível” como o Solr e Elasticsearch.
Este projeto tem a participação dos bolsistas Natália Queiroz e João Lanna.